This article covers our recommended approach to Disaster Recovery. How your Production environment is set up will largely determine how your Disaster Recovery (DR) environment is configured.
The purpose of a DR environment is to have a Production mirror deployed in a different geolocation/data-center to ensure Production uptime should the actual Production server go down.
Generally speaking, should the Production environment go down, all traffic is rerouted to the DR environment.
Below, we'll go over general DR options for the following deployment types:
Simple Install
For simple install production environments - meaning production is non-orchestrated and running on a single server and/or a separate database server - we recommend doing the following:
Application Server
- Provision a new application server for Disaster Recovery that should be the same specs (cpu, memory, disk)
- If a separate database server will not be provisioned but will instead have the database running locally, provision more memory to accommodate
- If running locally, MySQL runs inside of a container
Database Server (or MySQL running locally on Application Server)
- Provision a new database server for Disaster Recovery (also same specs)
- The DR database server can be a replication of production or completely isolated. The difference is in how content is migrated from Production to DR
- If isolated, we would schedule a backup/restore periodically to migrate content to DR from Prod
- Generally speaking, if there is no central DBA team managing the MySQL application database, we recommend deploying a single server hosting both the Metric Insights application and database for minimal effort/maintenance.
- The DR database server can be a replication of production or completely isolated. The difference is in how content is migrated from Production to DR
Copying Production Backups to DR and Restoring
- We would need a method of copying Full backup files from Production to the DR server. We can achieve this with an NFS volume mounted to both Prod and DR (to share MI backup files)
- We can schedule the DR server to restore content at some frequency + make sure cron is disabled on the failover server to prevent jobs from running. We don't want data/image collections running and bursts going out on the DR server while Production is still up and running (please see Caveat #5 in the diagram below)
- Backup files would then need to be moved to /opt/mi/backup so that it can be read inside the Web container
- We can restore the backup using our restore utility by running something like: mi-app-restore /opt/mi/backup/<name-of-prod-backup>.tar.gz -vv
- This restore command can be converted into a script and scheduled on cron to again, restore Production backups at some set interval
- Or, this restore command can be used to restore the most recent Production backup in the event Production goes down and there is a window in which to get DR up
- Some companies require immediate failover, others provide a cushion of up to several hours to accommodate
Redirecting Traffic to DR
- In the event Production goes down, you can do one of two things to route user traffic to DR:
- Route traffic to DR via Load Balancer (auto-detect)
- If there is no Load Balancer, remap DNS to DR server
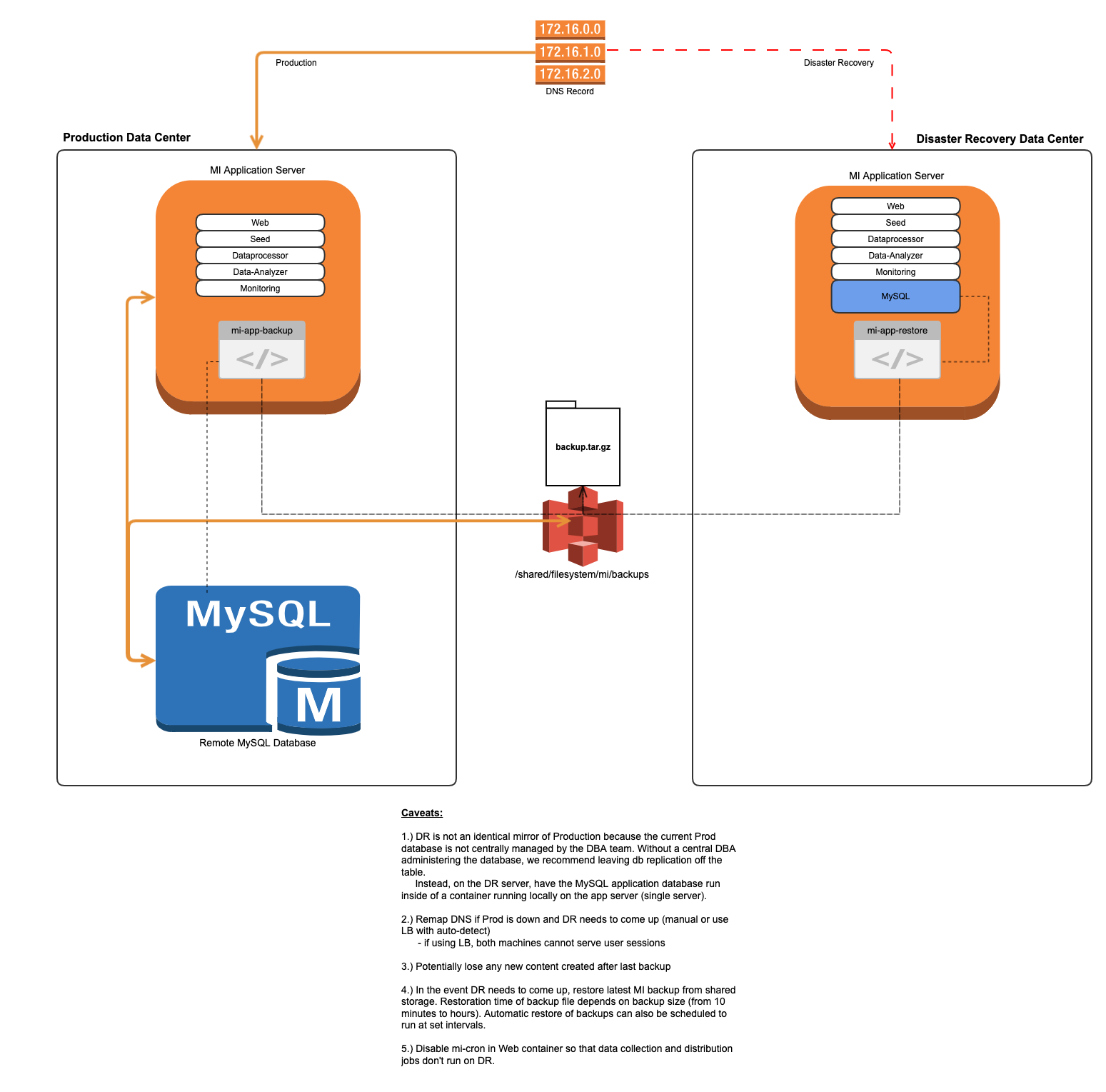
One thing to note here is that the DR server will absolutely need to have Metric Insights installed so that we can restore a backup in the event of an incident.
This means the DR server will need to be maintained in parallel with Production, i.e. make sure DR is up to date and on the same Metric Insights version as Production.
Kubernetes/OpenShift
Generally speaking, the DR environment for Kubernetes/OpenShift follows the same process as the Simple Install DR environment above:
- There needs to be a separate Disaster Recovery deployment in a different cluster > namespace in a different geolocation/data-center.
- The MySQL database is typically managed by a DBA team if the Metric Insights application is deployed in an orchestrated environment like Kubernetes or OpenShift. This means we can leverage the DBAs to ensure that there is a database server in the DR environment that is a mirror copy of Production.
- This DR database can be a replica or a separate/isolated database where content is migrated over via the Metric Insights backup/restore procedure.
- Create a process to migrate Production content to DR via backup/restore.
When Production goes down, reroute traffic to DR.
Another option, without explicitly having a separate DR environment is to have the Production namespace utilize worker nodes that are spread out in different data centers. Kubernetes/OpenShift already allows for High Availability in the sense that, should a service go down, it recognizes that and immediately redeploys the service in the next available node.
Leveraging this concept, you could potentially have worker nodes spread out geographically. The downsides are:
- The Kubernetes/OpenShift Master Node still requires a DR remediation plan (outside the scope of Metric Insights because it's at the cluster level).
- With nodes spread out serving the same application services, there could be a degradation in performance (network latency, etc.)
Docker Swarm
Disaster Recovery environments for Docker Swarm deployments will also follow the same process as the other deployments mentioned above:
- Create a copy of Production in a Disaster Recovery zone
- Ensure there's a replica of the MySQL database that serves just DR
- Create a process to migrate Production content to DR via backup/restore.
When Production goes down, reroute traffic to DR.
Disaster Recovery Testing
Once a Disaster Recovery environment is deployed, schedule a disaster recovery exercise where Production goes down and the Disaster Recovery environment must come up and handle user traffic. Make sure all SLAs are satisfied as part of the exercise.
Contact support@metricinsights.com for any questions.