This article describes how to establish dependencies between Datasets by using references in SQL statements and how these dependencies affect Trigger processing of the Datasets.
For details on building Datasets, see Create a Dataset from any Data Source.
1. Create a New or Access an Existing Dataset
Access the Dataset Editor and go to Data tab.
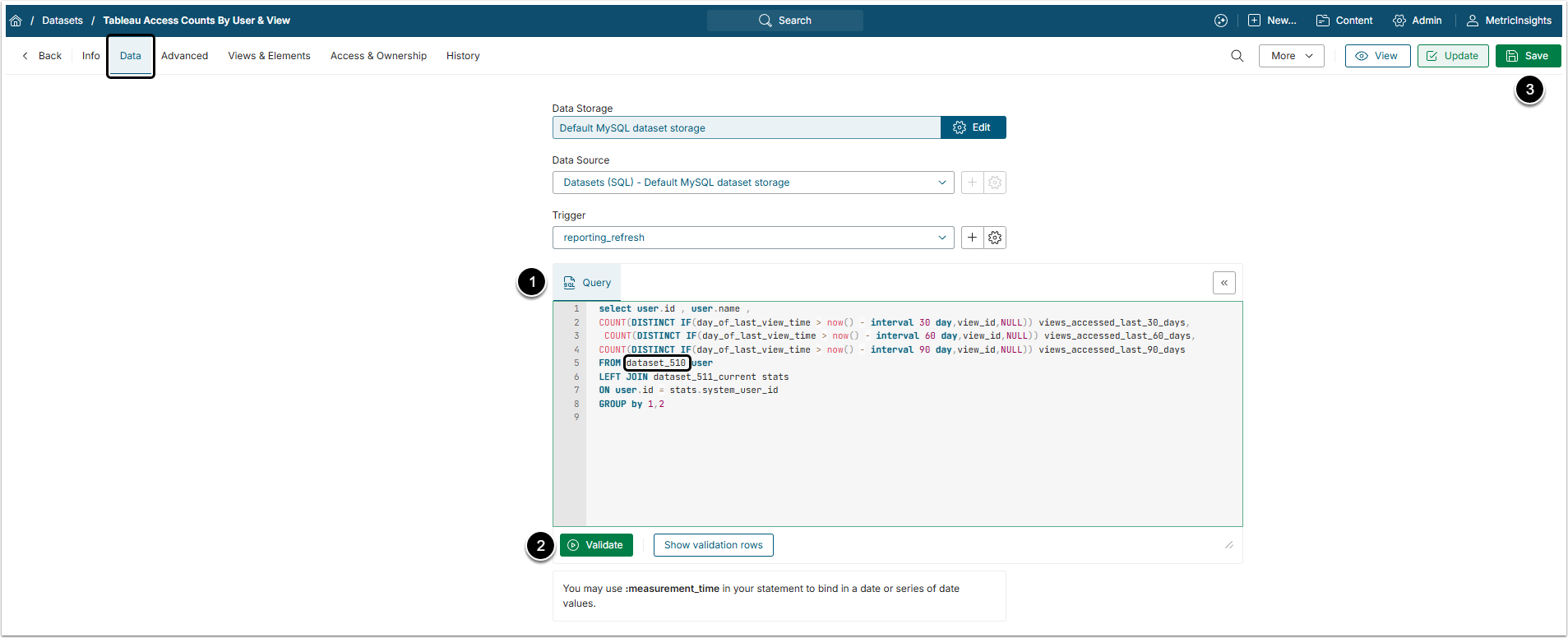
- Query: Enter an SQL command. You can reference any available Datasets.
- [Validate]
- [Save]
2. Check the Dataset Grids
2.1. View the Dependent Dataset
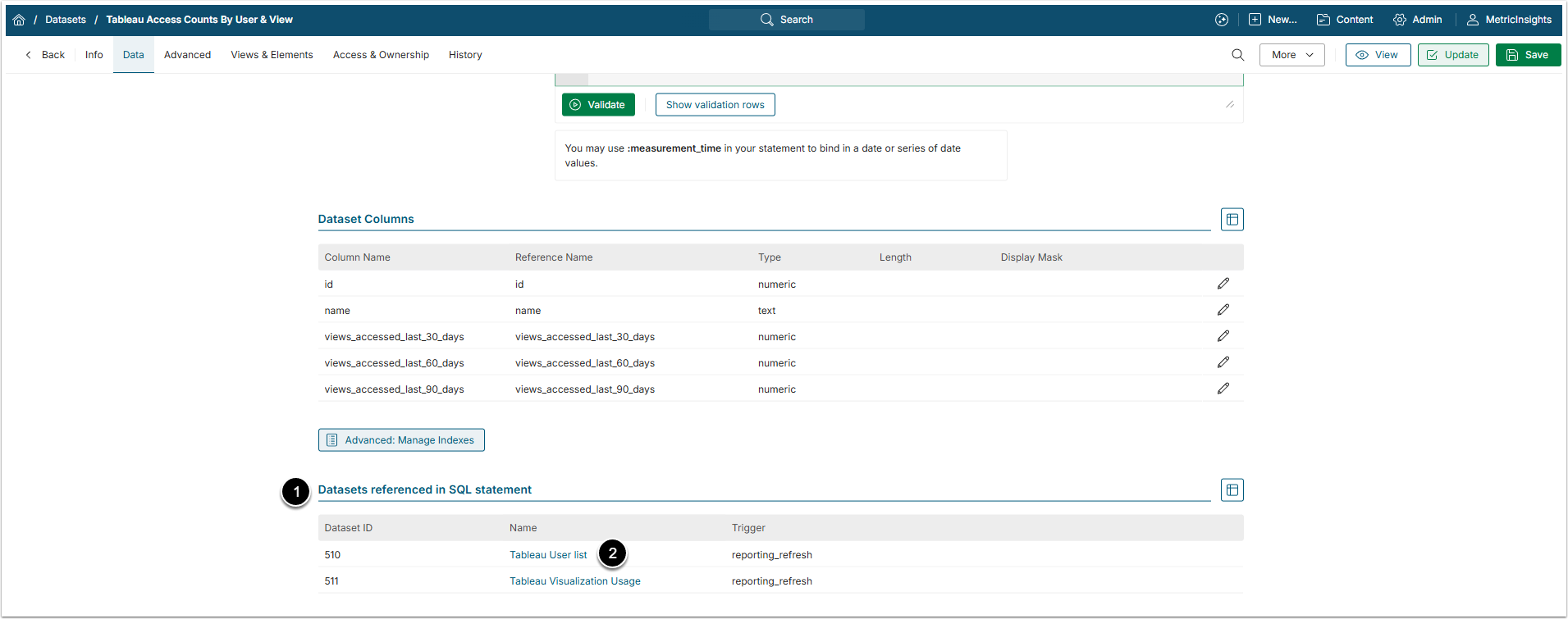
- The Datasets, whose data is used in the current Dataset, are displayed in the Datasets referenced in SQL statement grid.
- Access the referenced Dataset by clicking its Name link.
NOTE: Referenced Datasets that use different trigger (they are displayed in gray color) are not considered in the "ready for execution" dependency check during Trigger processing.
See Dataset Dependencies in Data Collection Trigger for more details.
2.2. View the Referenced Dataset
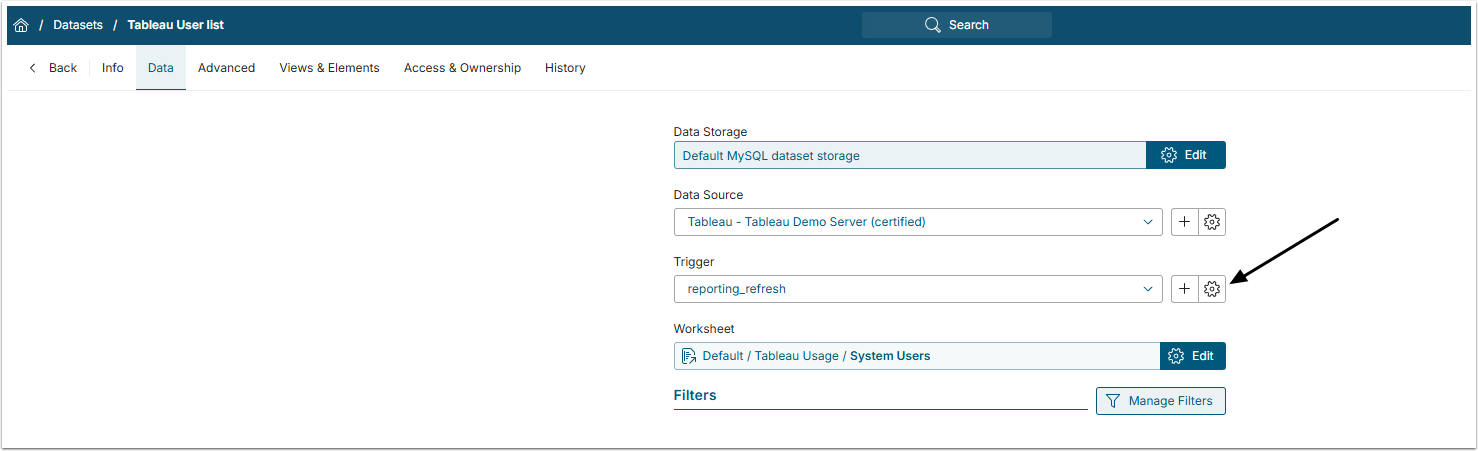
Access current Dataset's Trigger Editor by clicking on the gear icon.
NOTE: If fetch command for the current Dataset fails, Trigger processing for all the dependent Datasets will also fail.
Any error except the "0 rows fetched" condition is considered in this evaluation.
3. Check Dataset Dependencies in Trigger
Open the Recent Runs tab.
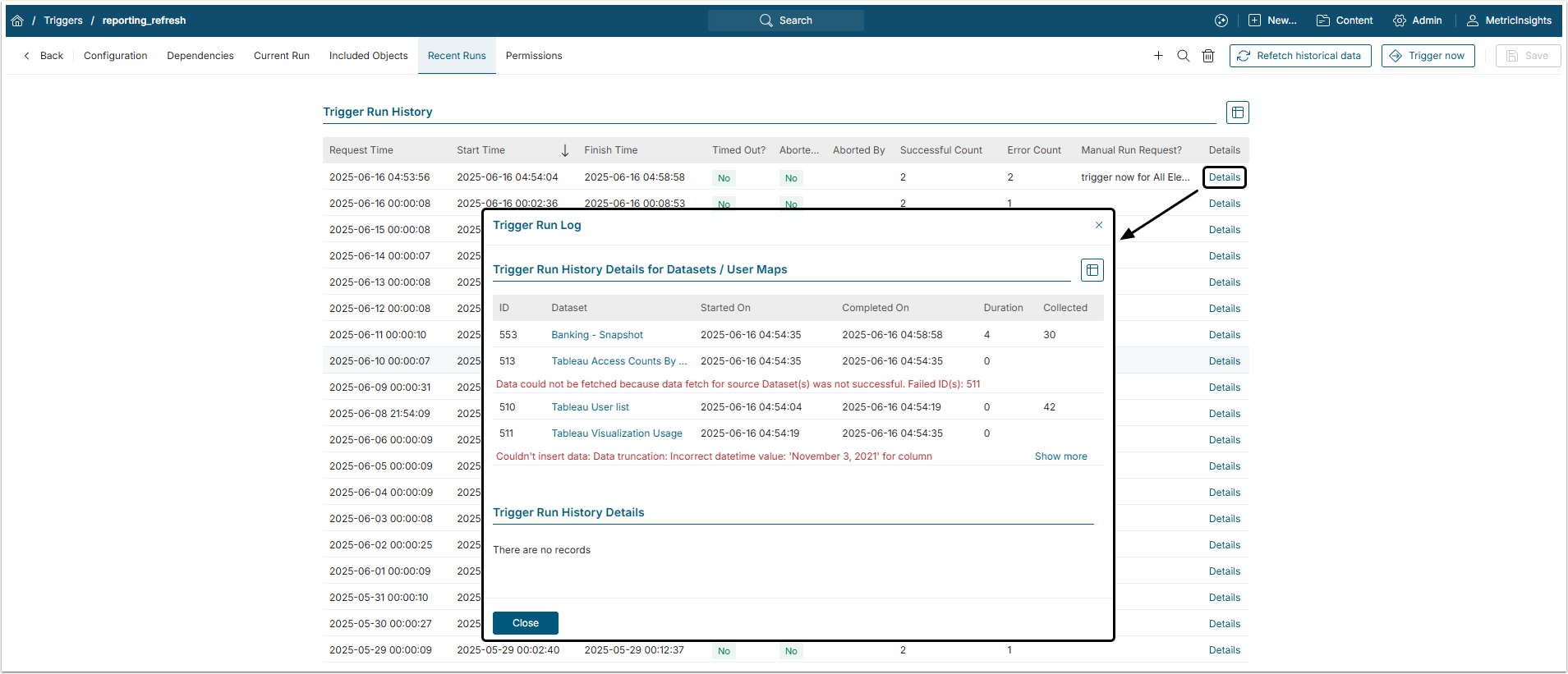
Click [Details] to view the last Trigger run's log. Note that the data for referenced Dataset is collected prior to the dependent Dataset's data.
NOTE: Only the "ready for execution" Datasets are picked at each stage of Trigger processing.
A Dataset is considered to be "ready for execution" if all the referenced Datasets that utilize the current Dataset's trigger have successfully been updated during Trigger processing.
4. Configure the Maximum Number of Dependent Stages
NOTE: Only System Administrators have access to System Variables, so this step can be performed by the System Administrator only.
Access Admin > System > System Variables

Find and configure the MAXIMUM_DATASET_DEPENDENCY_STAGES Variable, that specifies the maximum number of iterations during Trigger run to prevent infinite loops during Dataset updates.