While Concierge service works best on large LLM Models, such as GPT, it might be more convenient to use a local LLM Model. Unlike a large LLM Model, a local one does not require access through the firewall and thus demands fewer security considerations. Metric Insights allows for the connection of Concierge to a local LLM model, such as Google Gemma. This article describes how to establish a connection between Concierge and the Google Gemma LLM Model.
Prerequisites
To run a local LLM Model, a specialized separate GPU-optimized server that has at least 16GB of video RAM is required. You will need to install the Metric Insights Ollama on a separate server from the Metric Insights Application and Chatbot. Here are the recommended instance configurations, tested on their compatibility with Ollama:
- For AWS:
- g4dn.xlarge
- g5.xlarge
- g5.2xlarge
- p3.2xlarge
- For Azure:
- Standard_NC4as_T4_v3
- NV6ads_A10_v5
Ollama is installed on a separate server using the Metric Insights Ollama Installation Package. The Package can be downloaded via the link provided by your Metric Insights support specialist. Use the default approach to install the application on the dedicated server. An example of the default installation approach is described in detail in the Single Server Docker Deployment article.
Save the following information for Concierge configuration (see below):
- Address of the server, where Ollama is installed
- API Key

Concierge Settings
Access Admin > System > Search Setup and open Concierge tab
NOTE: In 7.1.0 version, the path has changed to Admin > System > Concierge Setup > General tab.
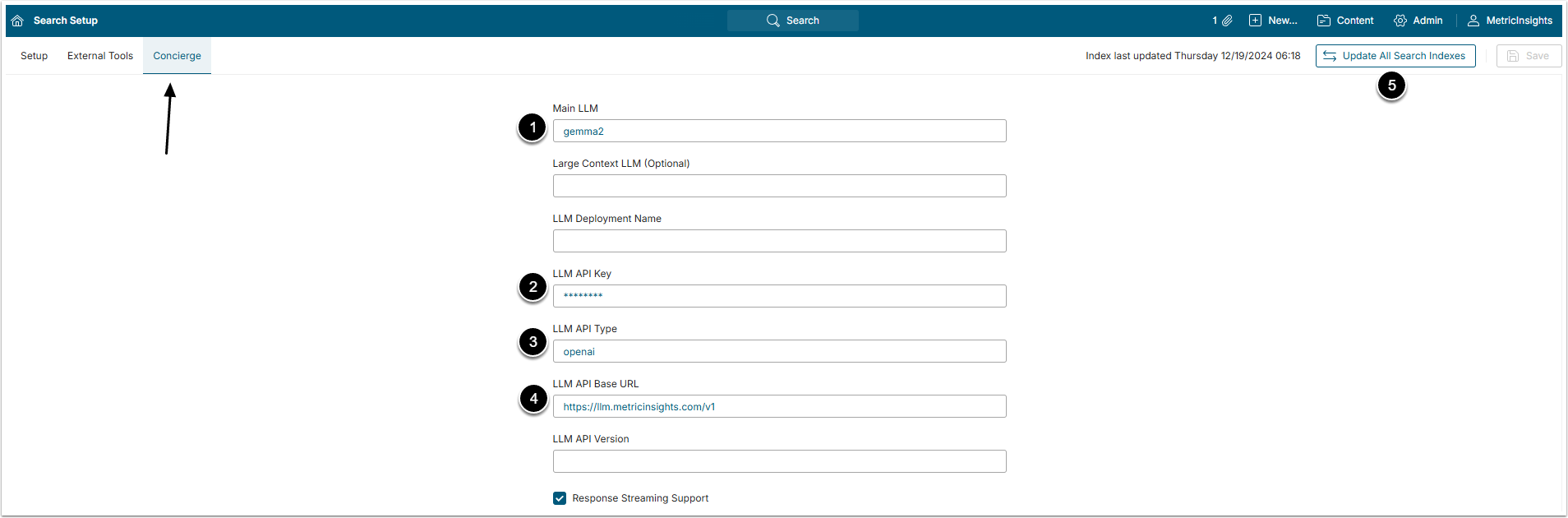
- Main LLM: Name the main LLM Model, used for Concierge
- LLM API Key: Insert the Ollama Secret API Key
- LLM API Type: Mention the API type, "openai" or "azure"
- LLM API Base URL: Type the server address
- [Update All Search Indexes]
Depending on the amount of data, indexing can take a lot of time, but it is necessary for Concierge to work correctly.
For more details on configuring Concierge, check the Install Concierge article.